OLLVM通用反平坦化研究
OLLVM简介
在介绍OLLVM之前,我们先简单了解下什么是LLVM:
The LLVM Project is a collection of modular and reusable compiler and toolchain technologies. Despite its name, LLVM has little to do with traditional virtual machines. The name “LLVM” itself is not an acronym; it is the full name of the project.
LLVM项目是一个模块化的、可重用的编译器和工具链集合。尽管它的名字与底层虚拟机(low level virtual machine)相似,但它并不是一个缩写,而是整个项目的全名。
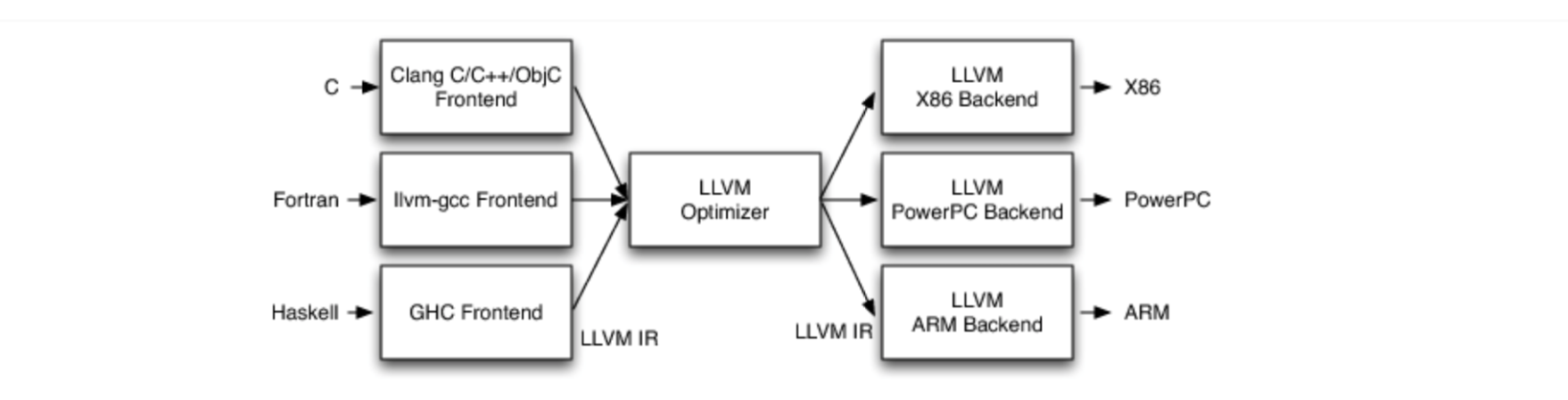
在LLVM架构下,不同的前端和后端使用统一的中间代码IR(InterMediate Representation)。由于采用了分离式架构,所以其复用性更强,增加语言/平台支持也相对容易。
Clang是LLVM架构下的C、C++及Objective-C的编译器前端,它主要负责通过词法、语法与语义分析建立AST,并生成IR(中间代码)。然后,优化器会加载当前LLVM IR所使用的Pass,对其进行层层优化。最后,由后端把优化后的代码转化为与平台相关的机器指令,流程如下所示:

需要说明的是,在LLVM中,优化以pass的形式实现,每个pass就代表一种优化,它分为三类:
1. Analysis Passes: 用于信息收集或计算,供其它Pass使用,调试相关信息或使程序可视化,对应路径为lib/Analysis
2. Transform Passes: 以某种方式转换程序,通常用于改变程序的dataflow/controlflow,对应路径为lib/Transforms
3. Utility Passes: 主要是提供了一些实用功能,不太适合划分到Analysis及Transform类别的passes就会被纳入其中
至于OLLVM(obfuscator-LLVM),则是基于LLVM Pass实现的开源代码混淆工具,用以增加逆向工程的难度。原版主要提供三种混淆模式,即控制流平坦化(Control Flow Flatten)、虚假控制流(Bogus Control Flow)及指令替换(Instruction Substitution)。尽管后期原作者不再维护该免费版本,但它提供的Pass混淆方案仍然具备很高的参考价值。目前,市面上对于原生代码的混淆技术主要都是在此基础上做的二次开发。
什么是控制流平坦化
控制流平坦化就是在不改变函数功能的前提下,将源代码中的if、while、for等控制语句替换成switch-case分支语句,从而将原始的程序结构打平,达到模糊各代码块之间关系的目的。其模型如下图所示: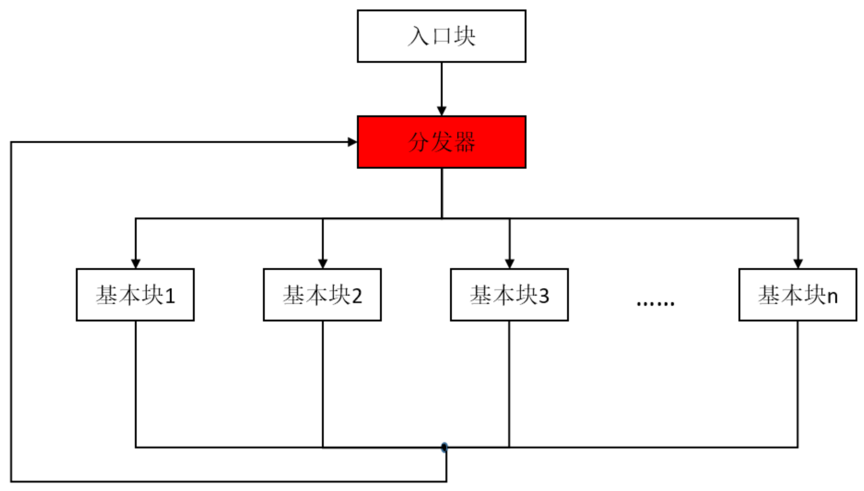
此外,配合基本块分割以及多次的平坦化操作,能够大大降低代码的可读性,从而有效提高破解门槛、保护代码逻辑。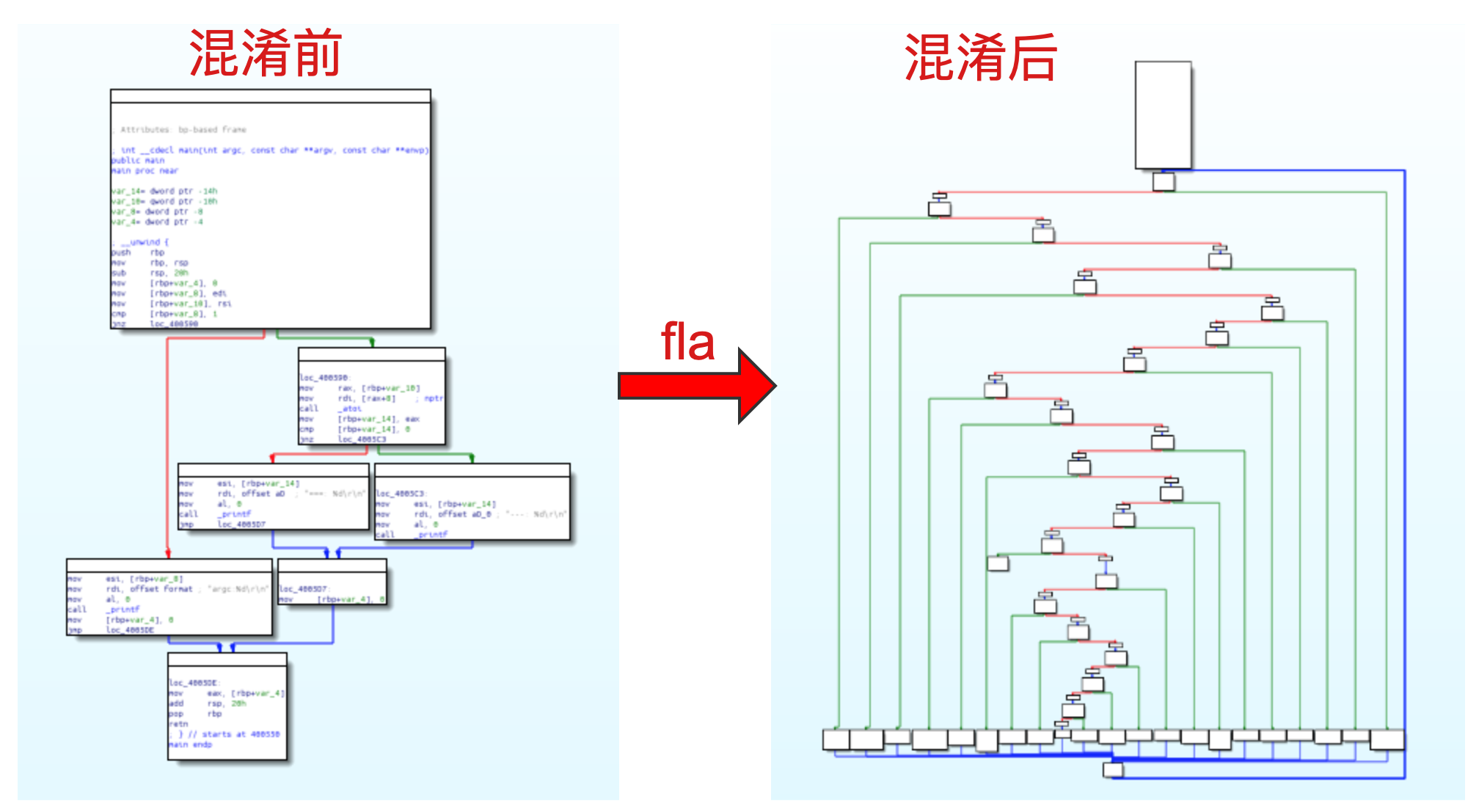
Control Flow Flatten的实现原理
接下来,将简单了解下平坦化的实现原理,在对它的混淆思路有较深的认识后,也能在一定程度上引导我们如何去做反混淆。原始的Ollvm中,平坦化Pass对应的代码路径为:/lib/Transforms/Obfuscation/Flattening.cpp。关于这部分的源码分析,网上有很多资料可以参考,这里就不再赘述。总的来说,大体流程如下:
- 消除当前程序中的switch语句,并转换成if-else这种分支调用
- 对所有的basic block进行遍历,放到一个容器中,并移除掉第一个基本块
- 检查第一个基本块中是否包含条件跳转分支,如果是的话就获取该条指令的地址、进行代码块切割
- 将第一个basic block与下一个basic block间的跳转关系删除,并在其末尾新建switchVar变量、赋予它一个随机值
- 创建while循环所需要的”loopEntry”、”loopEnd”这两个basic block,并在loopEntry中读取switchVar的值
- 创建switch语句中的default跳转对应的swDefault基本块,再通过建立以下连接,构成一个基于switch-case的大循环体
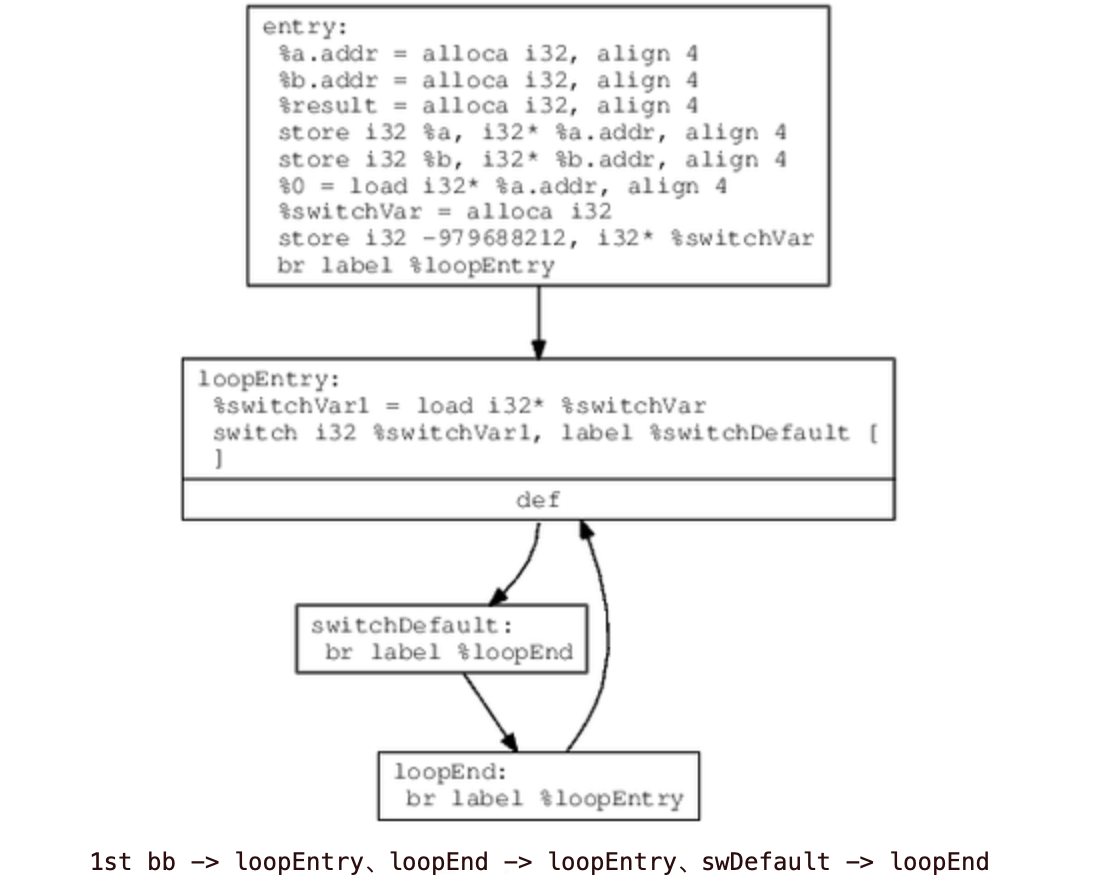
- 把保存在容器中的所有basic block都填充到这个switch框架里,并给每个基本块分配一个随机数作为它的case值
- 在每个case块下重设switchVar,使其执行完毕后再回到switch分支语句时,能顺利跳转到下一个case,直到程序结束
- 目标代码块没有后继块,意味着它是一个返回块,不需要处理
- 目标代码块只有一个后继块,将switchVar直接更新成后继BB对应的case值即可
- 目标代码块拥有两个后继块,也就是一个条件跳转分支,根据条件来选择下一条指令的blockId
反混淆的基本思想
基于前面的认知,可以知道对抗时主要围绕以下几点:
- 找到所有被碎片化的真实块
- 有效分析出这些真实块间的关系
- 对目标函数进行修复、恢复原始逻辑
关于真实块的查找这部分,网上的很多资料分享都是通过如下思路来进行甄别:
- 函数的开始地址为序言的地址
- 序言的后继为主分发器
- 后继为主分发器的块为预处理器
- 后继为预处理器的块为真实块
- 无后继的块为retn块
- 剩下的为无用块
这确实在某种程度上指明了参考方向,但它其实有个问题,就是当混淆很多次之后,这个结构会被破坏掉,并没有一个固定的模式,再加上些编译优化,类似预处理器这样具备明显特征的基本块就找不到了。所以,我们在实际应用中摒弃了这种通过相对关系来定位真实块的方法。
此外,据说Angr和Miasm这两个符号执行框架对arm64位指令集支持都不是很好,于是最终采用Unicorn模拟执行的方式来确定真实块之间的关系。
至于最后的修复环节,主要有两个方向:
- 打patch,即通过jump指令或者一些条件跳转指令试图将它们重新连接起来
- 提取出所有真实块的指令,并根据它们之间的关系,计算相对偏移,据此对函数进行重构
其中前者是不可靠的,因为真实情况远要复杂的多。譬如当一个真实块拥有三个及以上后继节点(通常是一个公共基本块)时,就无法直接patch。故从长期来看,基于位置偏移的指令重编译才是终极的解决方案。但这块需要对指令集有较深的认识,并且工作量也很大,所以当下使用的是半自动化选择性修复,存在一定缺陷。
基于Unicorn模拟执行框架实现平坦化的去除
找出所有的真实块
结合前面对平坦化的原理分析,我们知道它的本质逻辑就是把原始的基本块都碎片化,再通过switch-case语句,对函数的执行流进行重建。那么,在做反混淆的时候,就可以尝试根据主分发器将这些执行链给一条条的拆解出来,具体划分为三类:
- 入口链:原始函数代码的入口逻辑链,为序言到主分发器的执行路径
- 循环链:入口及出口均为主分发器的流程链,对应混淆过程中的循环体
- Return链:指代入口为主分发器,出口为目标函数结束地址的流程链
其中,入口链比较特殊,因为没有分发器这样的控制块,所以在不考虑虚假控制流的情况下,它里面的代码全都是真实指令。于是,问题就变成了如何找出循环链及Return链中的真实块。这里有个思路,就是由于在原始程序中,每个真实块都有唯一的随机数,所以我们可以反过来利用这种对应关系进行定位。
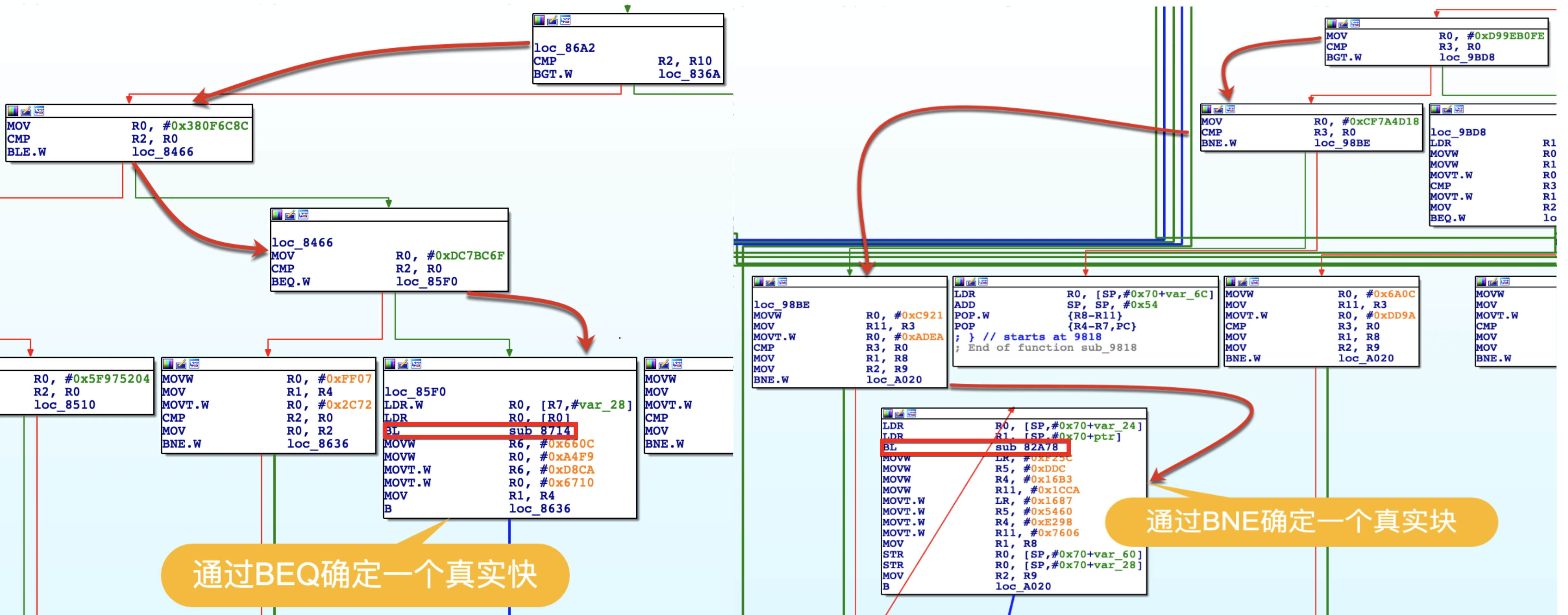
如上图所示,可以注意到尽管Ollvm在编译的时候会采用二分的思想做路径优化,进而产生很多类似BLE、BGT这样的区间判断指令来做分发、寻路,但若想要定位到一个真实块,就仍必须得有个绝对的比较指令,即 BEQ 或者 BNE。
所以,针对那些非入口链的执行路径,我们可以从主分发器开始向下查找,当首次匹配到 BEQ 或者 BNE 这种绝对比较的跳转指令时,就能定位出对应流程链中的真实块入口地址。然后,基于真实块后面通常跟的也是真实块的逻辑,从而识别出全部的真实基本块。
这里有个稍微需要注意的点,就是前面提到的”真实块连续性”问题。它其实是有例外的,因为每条循环链都要在末尾重新修改switchVar的值,用以指定下一条执行链。然后,这部分代码在优化时可能会脱离真实的指令部分,成为一个独立的块,如下:
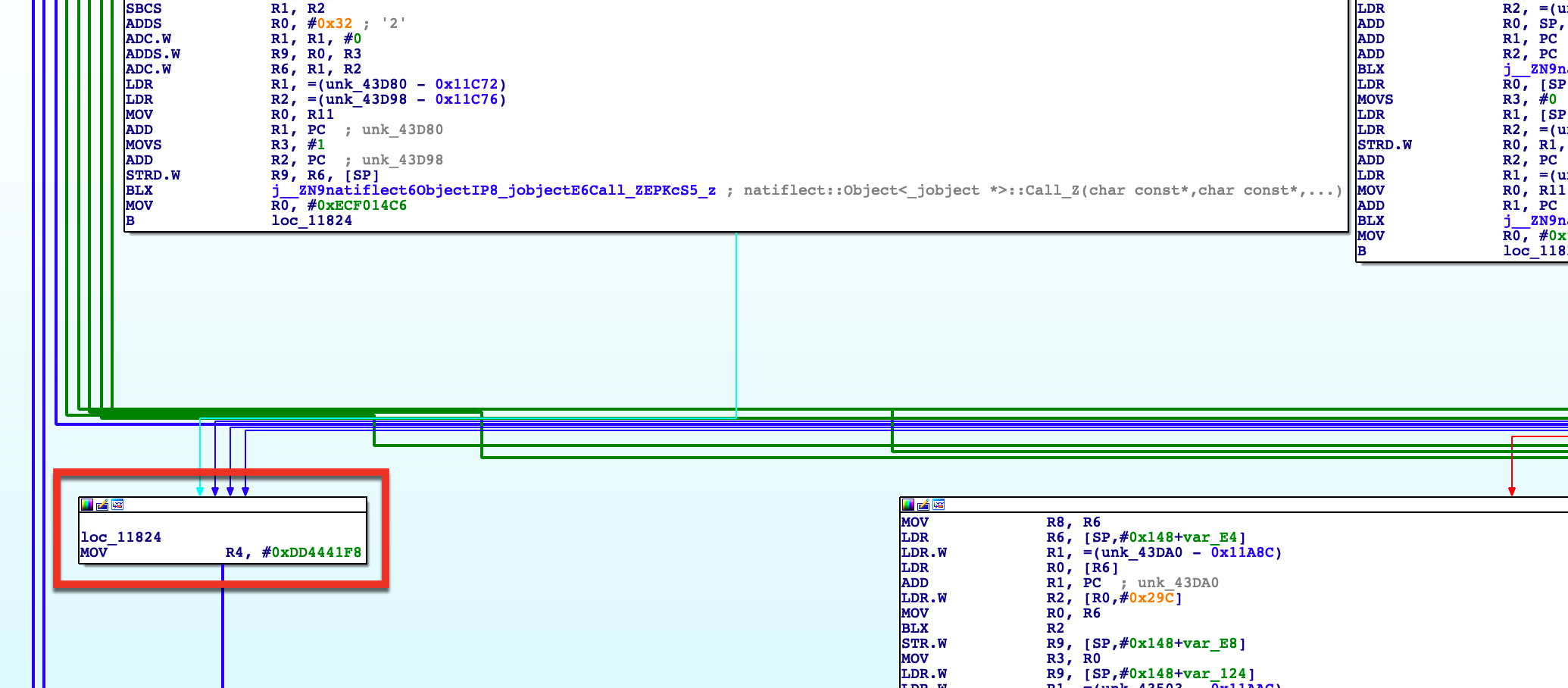
这就导致我们找出来的”真实块”可能混有一部分的虚假块,针对这种情况,有个比较简单的思路,就是对每条循环链中的末位基本块进行过滤。如果它的指令个数小于3,那么它大概率就是在做一些跟switchVar相关的赋值操作,属于垃圾代码。但是也可能会带来一定的误伤,所以这块还是需要人工介入进行排查,或者后期引入机器学习来做特征码识别加以解决。
至于如何确定主分发器,这个就非常简单啦,直接遍历目标函数下的所有基本块,并计算每一个Block的引用次数,数量最多的那个就是主分发器。
通过模拟执行确认各真实块之间的关系
前面已经把所有的真实块都识别了出来,接下来就是要找出它们之间的关系。然后,由于每条执行链中的前后关系是已经明确下来的,所以我们只需确认这些流程链之间的顺序就好。这也就意味着上一步中可能携带的”虚假块”不会影响到这里的操作,它所带来的干扰主要是在修复层面,即一个无效块被认知为真实块的情况下,导致其拥有复数个后继节点时的Patch问题。
继续回来看”真实块关系确认”的问题,方才已经提到主要思路就是要找出各流程链之间的执行顺序,那么具体要怎么操作呢?首先,我们已经知道了在每条执行流的末尾都会去重设switchVar,以指定它要去寻路的下一个真实块。然后,据此为突破点,通过对除Return链以外的流程链进行模拟执行,就可以计算出它回到主分发器时的值。根据这个值,就能把前面找到的流程链给关联起来,拼接、合并成由一系列真实块所组成的逻辑链。
然后,需要注意的是,在ARM中有很多IT(T)、CSEL等条件指令,对应那种if-else分支语句。其出现的目的,主要就是能够起到指令压缩的作用,占用更小的空间、提高执行效率。但Unicorn框架是没法识别这类指令的,所以我们得先将这些条件选择指令转义成条件跳转指令,从而切割基本块,再去做模拟执行。
此外,通过switchVar变量来关联各流程链在实际应用时会遇到个问题,就是其存储形态不确定。它有可能是个寄存器,也可能是个栈变量,这样就给自动化带来了困难。于是,我们又想到了一个替代方案,即利用执行流返回主分发器时的上下文环境来做关联,因为每条流程链的出口上下文环境里必然存在用于寻路的ID号。对比前者而言,通用性更强,实施步骤如下:
- 在Unicorn虚拟机实例中自定义强制模式(force mode)及常规模式(nature mode),并添加指令级Hook回调
- 强制模式(force mode):若识别到当前指令是条跳转指令,则会根据当前地址和指令长度算出下一条指令的地址,写入到PC寄存器,从而实现对所有跳转指令的禁用,以确保代码能够按照既定的路径执行
- 常规模式(nature mode):对比 force mode 而言,放开了前面的那种限制条件,允许跳转范围在函数内部的指令运行,并且当指令地址等于前面记录的真实块入口地址或函数的结束地址时,就自动停下、防止跑飞
- 将当前的虚拟机实例设置为 force mode,对所有的入口链进行模拟执行,从而获取其运行到主分发器时的上下文
- 进一步的,再根据前面得到的上下文环境,对所有的循环链进行模拟执行,得到它们返回主分发器时的出口上下文
- 模式切换到 nature mode,以每条循环链的出口上下文,调用主分发器做模拟执行,找出对应的下一个真实块入口地址
- 根据上述信息,对所有的流程链进行合并、生成逻辑链,还原被替换的选择指令、恢复函数原始的CFG图
如是一来,我们就成功的找出了所有真实块之间的关系。其实到这里,已经可以在一定程度上辅助做逆向分析,只是不能F5看伪代码。接下来,只需要将那些虚假块给NOP掉,再通过 patch 或者 rebuild 的方式对目标函数进行重建,就能够恢复函数的原始逻辑了。
然后,还需要补充说明的是,做平坦化去除的时候,一定要先干掉虚假控制流!这点非常重要,否则将互相干扰,直接影响到该环节的输出。
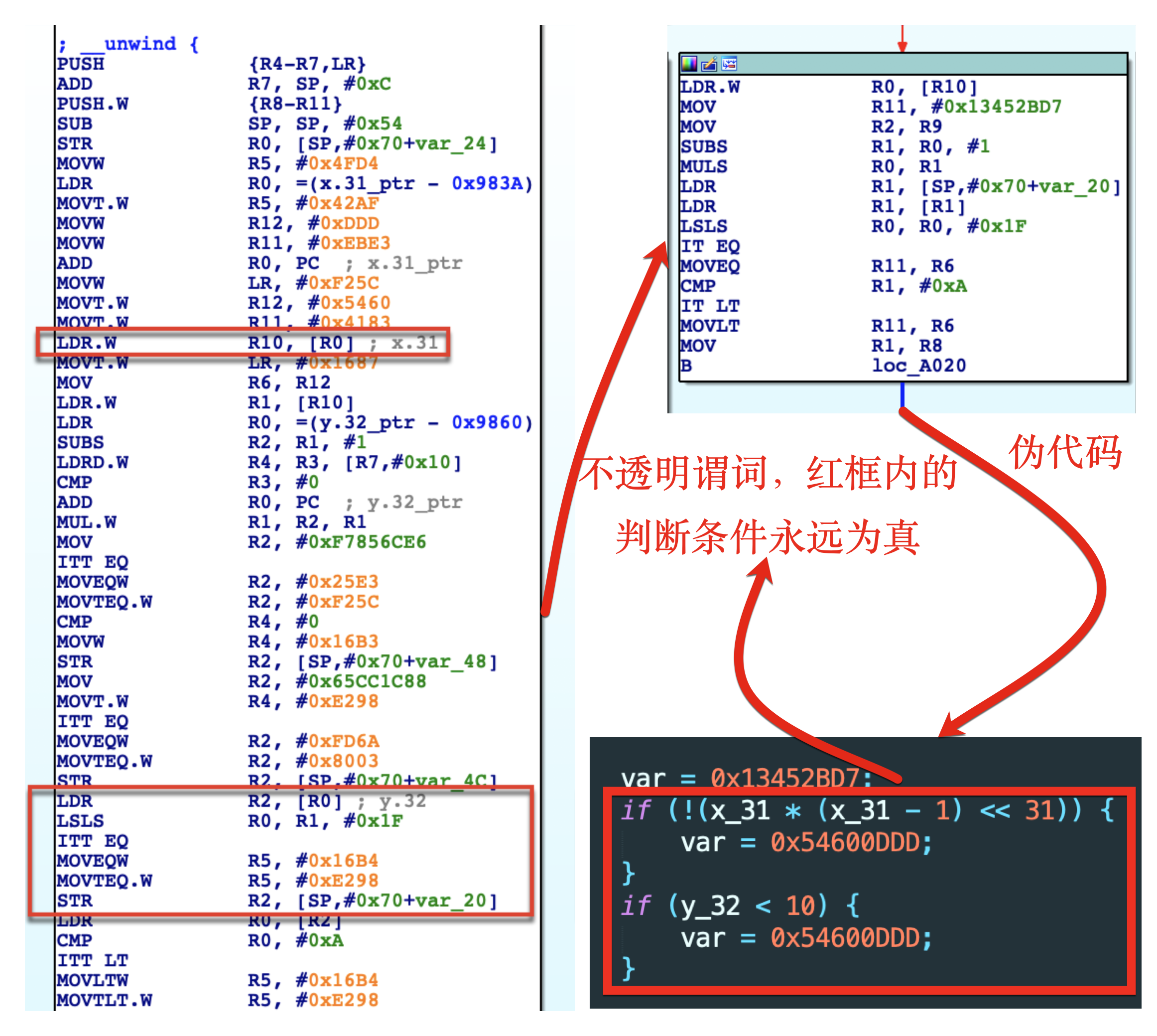
如上图所示,若我们不去管这块,那么模拟的时候便会跑到一些原本根本不会执行到的假分支,这样在确认真实块之间的关系时,就会出现问题。怎么办呢?之前个人曾参考葫芦娃在看雪上发布的Hex-Rays: 十步杀一人,两步秒OLLVM-BCF这篇文章,想到了一个临时的补救措施:
- 先把这些不透明谓词对应的变量用
const修饰为只读,然后把它的值改为0 - 选择性的去拆解条件选择指令,只对覆盖到基本块尾部的条件选择指令进行转义
考虑到switchVar通常都是在基本块的末尾被重新赋值,只有它会直接决定真实块的走向。至于其他的条件判断则不会在该时机产生影响,所以就可以不用拆解。这样做的好处是,一来能减少计算的复杂度,二来就是当存在上面的这种虚假控制流时,让Unicorn虚拟机直接略过ITT类条件选择指令,走向正确的分支。

但它也随之带来了很多麻烦,因为后面发现在引入虚假控制流后,其整体结构变得非常复杂,经常出现如下这种情况:
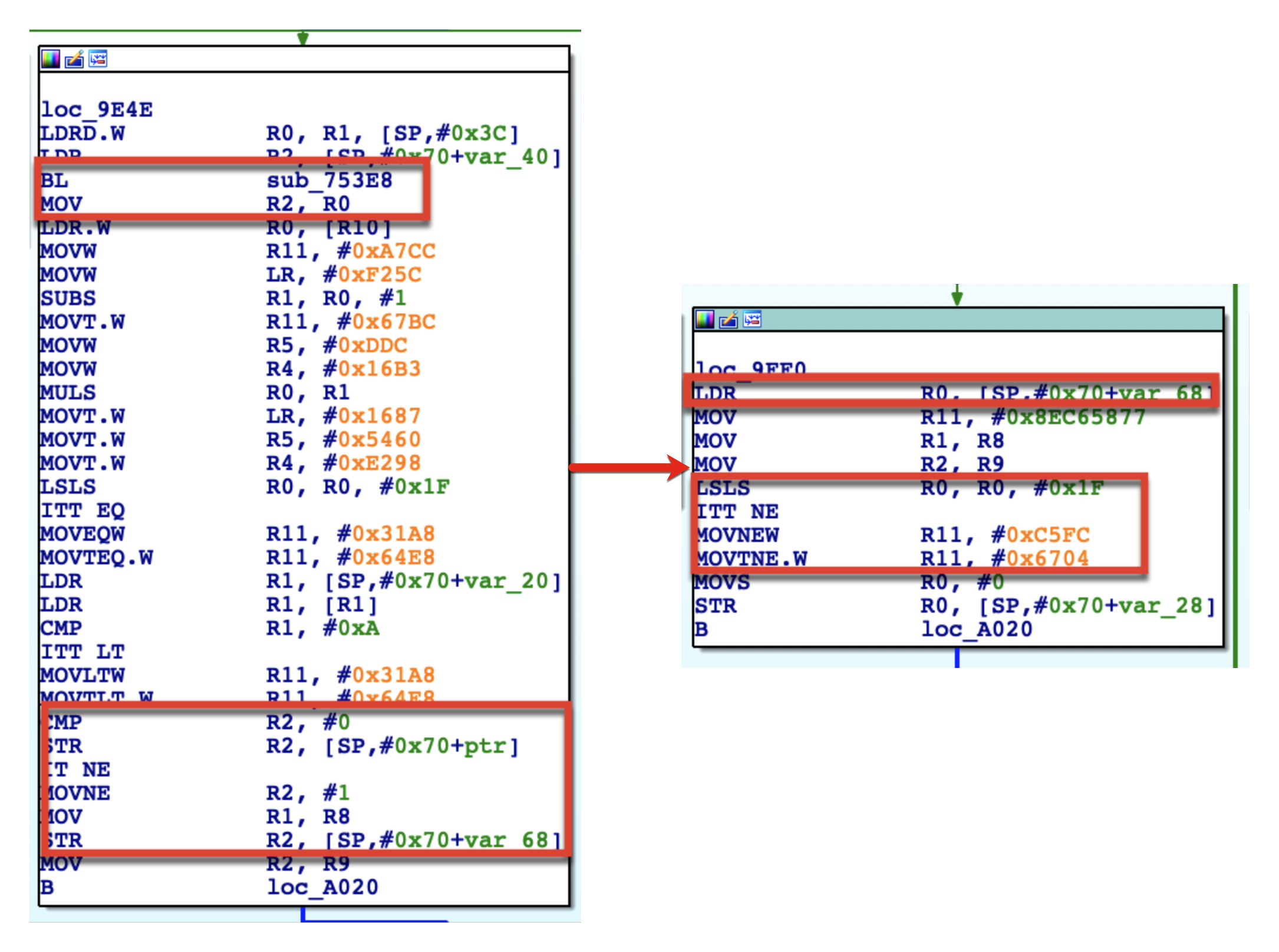
以上图为例,loc_9E4E这个基本块的主要行为就是调用外部的偏移函数sub_753E8,检查它的返回值是否为0,然后据此存个布尔值到[SP,#0x70+var_68]变量中。需要注意的是,这段代码加了虚假控制流,其出口ID固定为0x64E831A8,这说明它的后继节点只有一个。然后,通过分发寻路找到了loc_9FF0基本块,它的作用就是读取[SP,#0x70+var_68]变量,并左移31位,再根据这个条件判断赋给switchVar不同的值。于是,这就产生了一个问题,即前面的补救措施反而不能处理这种需要去拆解的条件指令了。
像上面那种情况,其实可以发现原本的条件判断就在loc_9E4E中,但因为加了虚假控制流,多了些假分支。所以在做平坦化的时候,就会先去打平那些由BCF所带来的分支块,以至于原始的条件判断被压缩到了一个临时变量里,再到新的基本块中进行处理。然后,这时候我们发现会影响到出口ID的条件选择指令不一定刚好覆盖到基本块的末尾,它下面可能还有2、3条指令。
既然如此,就说明前面那种临时的解决方案是行不通的。在处理平坦化之前,必须要先搞定虚假控制流的问题。葫芦娃的那篇文章,角度虽然清奇,但只能从借由IDA的F5功能优化掉这部分的伪代码。从CFG的角度,虚假块依然存在,并没有被消除。这样当我们通过模拟执行所有路径获取对应的出口上下文时,就会把一些假分支也带上,从而返回个错误的输出结果。所以,目前对于那些同时上了平坦化和虚假控制流的样本,处理能力就比较受限。当下能想到的办法,就是先结合伪代码把基本块中跟虚假指令相关的条件分支给过滤掉,然后再按照前面的思路分割基本块、模拟执行找关系。然而,当处理一个大型函数时,光是这种人工操作就很费事。。
重建各真实块之间的联系、恢复原始逻辑
在经过前面两轮的分析后,我们终于走到了修复阶段。然后,早前就已经说明,Patch这种方案是不可靠的,没法完全自动化。但由于目前不具备指令重编译的能力,所以只能先选用这种方案,再结合具体场景选择性是否要人工介入,步骤如下:
- NOP掉分发器、公共前缀基本块(指代switch结构预处理基本块)等虚假块
- 根据逻辑链,找出每个真实块的所有后继,并根据它们的数量以及跳转范围,来判断是否可直接Patch
- 目标真实块只有一个后继,这种就很简单了,直接在该基本块的末尾进行patch、指向下一个节点的地址就好
- 目标真实块拥有两个后继,到这里就得看情况了,不一定能自动修复的,大体可分为两类:
- 该真实块中包含条件选择指令,那么在该条指令地址及基本块尾部进行patch即可
- 这里需要注意的是,诸如BGT这样的条件跳转是有长度限制的,所以得先计算下条件分支指令所在的地址与目标地址的偏移值,如果过大就要做指令分割
- 该真实块中不包含条件选择指令,说明让它产生分歧的原因不在其内部,而是由于它的前驱。也就是说,它存在代码复用的情形,不同的调用者会得到不同后继。
- 这种情况,我们只能让它先指向一个后继块,然后在Nop后的空白区域里把这部分代码给拷贝一遍,并重新建立它跟另一个前驱块和后继块之间的联系
- 该真实块中包含条件选择指令,那么在该条指令地址及基本块尾部进行patch即可
- 至于那种存在3个及以上后继节点的真实块,几乎可直接判定它就是一个公共块,处理思路与前面类似
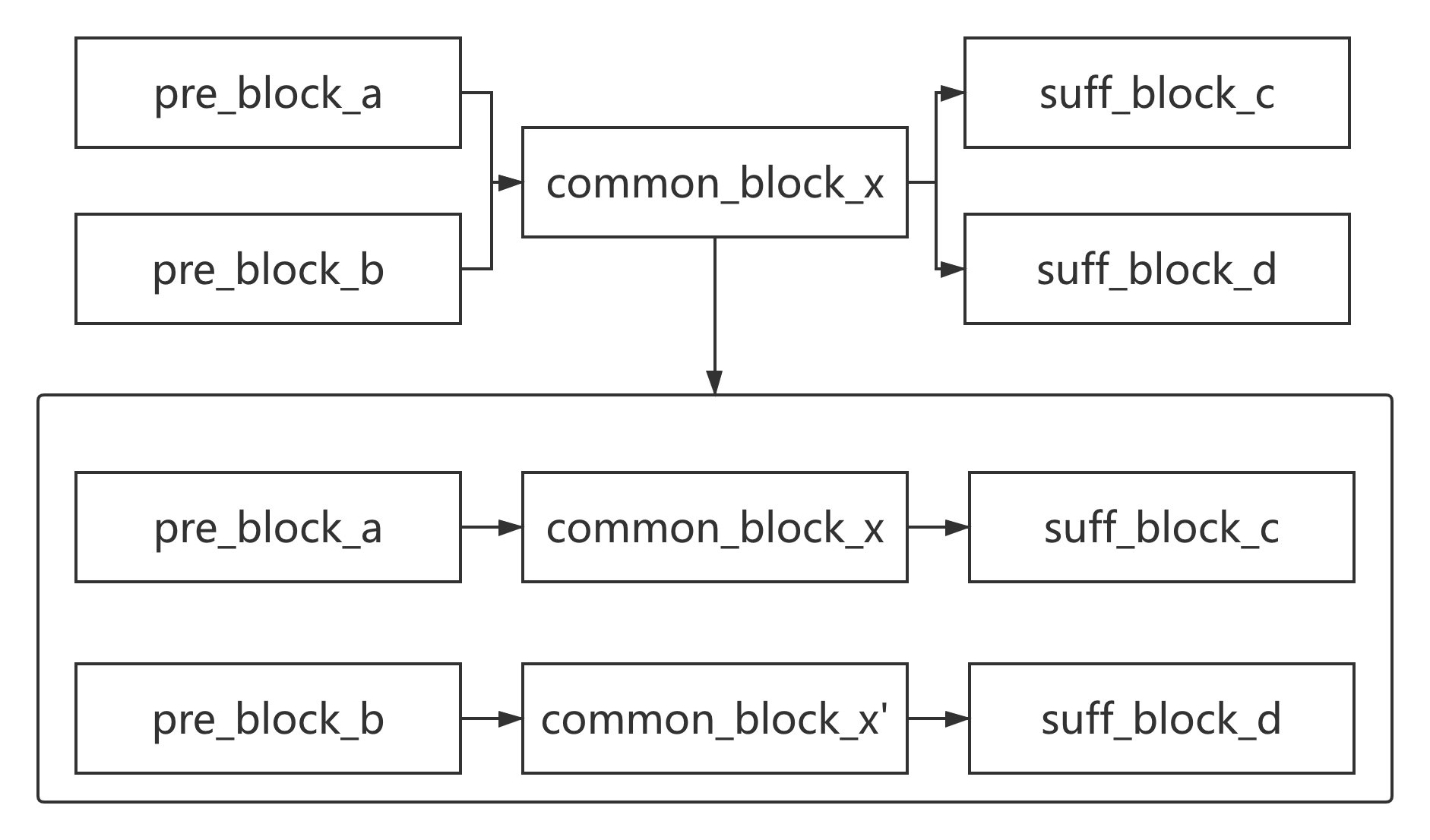
最后,我们再来简单处理一个带有虚假控制流的反混淆案例,测试下效果:
这个函数比较简单,所以虚假控制流基本没带来什么影响,对应的伪代码如下:
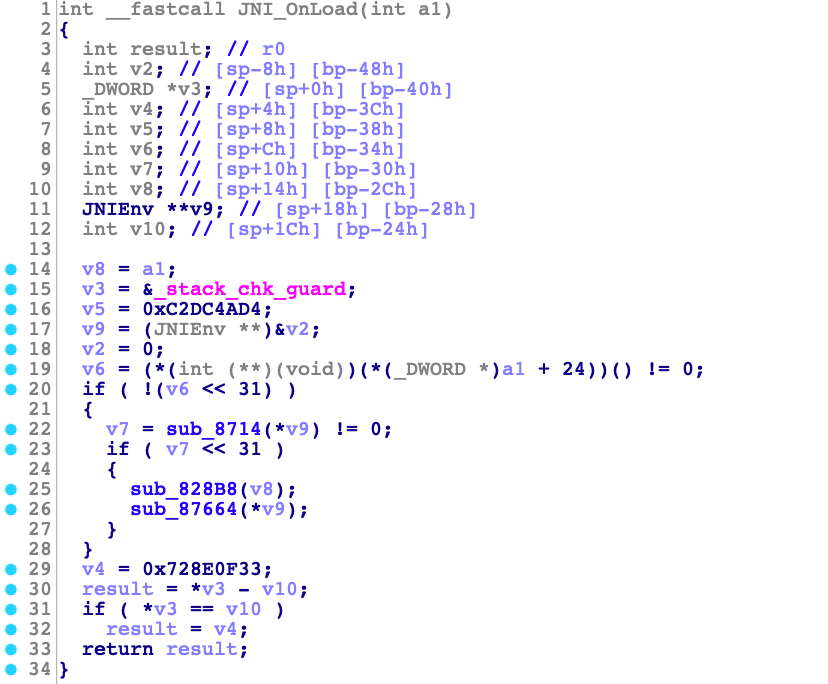
当然,我们其实是可以处理一些复杂函数的,但前提是要先去过滤掉虚假控制流,人工介入的成本较高,这里就不展示了。
总结
由于反混淆本身是套链式操作,每一步的输出结果都会对后面的输入造成影响,而这些过程中又有很多的细节以及需要注意的问题,所以可能就是无法完全自动化。但这种去平坦化的思路确实是比较通用的,只是在引入虚假控制流等其他混淆模式后,复杂度又上升了一个层次。所以实际应用时,必须要先去除掉虚假控制流所带来的干扰,再来做反平坦化。